epicontacts: Manipulation, Visualisation and Analysis of Epidemiological Contact Data
2023-03-28
Source:vignettes/epicontacts.Rmd
epicontacts.RmdIntroduction
epicontacts aims to facilitate manipulation, visualisation and analysis of epidemiological contact data. Such datasets inherently have network components, in which nodes are typically cases and reported contacts or exposures are (directed or undirected) edges. This package provides a convenient data structure as well as functionality specific to handle these data.
Loading Data
epicontacts provides a convenient structure to store heterogeneous epidemiological contact network data (i.e. nodes and edges) in a single object. The epicontacts class must contain two components: a line list and a contact dataset.
Each row of the line list should represent unique observations of cases, and each row of the contact list should represent unique pairs of contacts. Each can include arbitrary features, but both datasets should share an identification scheme.
Example Dataset
The example that follows will use the mers_korea_2015, which is a dataset (in list format) distributed in the outbreaks package.
str(mers_korea_2015)## List of 2
## $ linelist:'data.frame': 162 obs. of 15 variables:
## ..$ id : chr [1:162] "SK_1" "SK_2" "SK_3" "SK_4" ...
## ..$ age : int [1:162] 68 63 76 46 50 71 28 46 56 44 ...
## ..$ age_class : chr [1:162] "60-69" "60-69" "70-79" "40-49" ...
## ..$ sex : Factor w/ 2 levels "F","M": 2 1 2 1 2 2 1 1 2 2 ...
## ..$ place_infect : Factor w/ 2 levels "Middle East",..: 1 2 2 2 2 2 2 2 2 2 ...
## ..$ reporting_ctry: Factor w/ 2 levels "China","South Korea": 2 2 2 2 2 2 2 2 2 1 ...
## ..$ loc_hosp : Factor w/ 13 levels "365 Yeollin Clinic, Seoul",..: 10 10 10 10 1 10 10 13 10 10 ...
## ..$ dt_onset : Date[1:162], format: "2015-05-11" "2015-05-18" ...
## ..$ dt_report : Date[1:162], format: "2015-05-19" "2015-05-20" ...
## ..$ week_report : Factor w/ 5 levels "2015_21","2015_22",..: 1 1 1 2 2 2 2 2 2 2 ...
## ..$ dt_start_exp : Date[1:162], format: "2015-04-18" "2015-05-15" ...
## ..$ dt_end_exp : Date[1:162], format: "2015-05-04" "2015-05-20" ...
## ..$ dt_diag : Date[1:162], format: "2015-05-20" "2015-05-20" ...
## ..$ outcome : Factor w/ 2 levels "Alive","Dead": 1 1 2 1 1 2 1 1 1 1 ...
## ..$ dt_death : Date[1:162], format: NA NA ...
## $ contacts:'data.frame': 98 obs. of 4 variables:
## ..$ from : chr [1:98] "SK_14" "SK_14" "SK_14" "SK_14" ...
## ..$ to : chr [1:98] "SK_113" "SK_116" "SK_41" "SK_112" ...
## ..$ exposure : Factor w/ 5 levels "Contact with HCW",..: 2 2 2 2 2 2 2 2 2 2 ...
## ..$ diff_dt_onset: int [1:98] 10 13 14 14 15 15 15 16 16 16 ...What features are in the line list?
colnames((mers_korea_2015$linelist))## [1] "id" "age" "age_class" "sex"
## [5] "place_infect" "reporting_ctry" "loc_hosp" "dt_onset"
## [9] "dt_report" "week_report" "dt_start_exp" "dt_end_exp"
## [13] "dt_diag" "outcome" "dt_death"What about the contact dataset?
colnames((mers_korea_2015$contacts))## [1] "from" "to" "exposure" "diff_dt_onset"
Creating epicontacts Object
In order to create the epicontacts object, both the line list and contact data frames must be passed to make_epicontacts(). This function accommodates instances when the respective identifiers are not the first columns of these data frames (see the “id”, “from” and “to” arguments). make_epicontacts() can also account for contact networks that have a direction (see “directed” argument).
merskor15 <- make_epicontacts(linelist = mers_korea_2015$linelist,
contacts = mers_korea_2015$contacts,
directed = FALSE)
class(merskor15)## [1] "epicontacts"
summary(merskor15)##
## /// Overview //
## // number of unique IDs in linelist: 162
## // number of unique IDs in contacts: 97
## // number of unique IDs in both: 97
## // number of contacts: 98
## // contacts with both cases in linelist: 100 %
##
## /// Degrees of the network //
## // in-degree summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 0.00 1.00 1.21 1.00 39.00
##
## // out-degree summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 0.00 1.00 1.21 1.00 39.00
##
## // in and out degree summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 0.00 1.00 1.21 1.00 39.00
##
## /// Attributes //
## // attributes in linelist:
## age age_class sex place_infect reporting_ctry loc_hosp dt_onset dt_report week_report dt_start_exp dt_end_exp dt_diag outcome dt_death
##
## // attributes in contacts:
## exposure diff_dt_onsetData Manipulation
Access Unique Identifiers
The summary() method above provided counts for the number unique cases in both the contact and line list. The get_id() function retrieves similar information but as vectors of identifiers. This can be parameterized as follows:
- linelist: IDs in the line list data
- contacts: IDs in the contact dataset (“from” and “to” combined)
- from: IDs in the “from” column of contact datset
- to IDs in the “to” column of contact dataset
- all: IDs that appear anywhere in either dataset
- common: IDs that appear in both contacts dataset and line list
What are the first ten IDs in the contacts dataset?
## [1] "SK_14" "SK_16" "SK_6" "SK_87" "SK_1" "SK_15" "SK_76" "SK_11"
## [9] "SK_12" "SK_118"How many IDs are common to both?
## [1] 97Subsetting
The subset() method for epicontacts objects allows for, among other things, pruning of networks based on values of node and edge attributes. These values must be passed as named lists to the respective argument.
subset(merskor15, node_attribute = list("outcome" = "Dead", "sex" = "M"),
edge_attribute = list("exposure" = "Emergency room"))##
## /// Epidemiological Contacts //
##
## // class: epicontacts
## // 14 cases in linelist; 33 contacts; non directed
##
## // linelist
##
## # A tibble: 14 x 15
## id age age_class sex place_in~1 repor~2 loc_h~3 dt_onset dt_report
## <chr> <int> <chr> <fct> <fct> <fct> <fct> <date> <date>
## 1 SK_3 76 70-79 M Outside M~ South ~ Pyeong~ 2015-05-20 2015-05-20
## 2 SK_6 71 70-79 M Outside M~ South ~ Pyeong~ 2015-05-24 2015-05-28
## 3 SK_23 73 70-79 M Outside M~ South ~ Konyan~ 2015-05-31 2015-06-02
## 4 SK_24 78 70-79 M Outside M~ South ~ Konyan~ 2015-05-31 2015-06-02
## 5 SK_28 58 50-59 M Outside M~ South ~ Pyeong~ 2015-05-29 2015-06-03
## 6 SK_36 82 80-89 M Outside M~ South ~ Konyan~ NA 2015-06-04
## 7 SK_38 49 40-49 M Outside M~ South ~ Dae Ch~ 2015-05-23 2015-06-05
## 8 SK_64 75 70-79 M Outside M~ South ~ Samsun~ 2015-06-04 2015-06-06
## 9 SK_81 62 60-69 M Outside M~ South ~ Samsun~ NA 2015-06-07
## 10 SK_83 65 60-69 M Outside M~ South ~ Konyan~ 2015-06-01 2015-06-07
## 11 SK_84 80 80-89 M Outside M~ South ~ Dae Ch~ 2015-06-05 2015-06-07
## 12 SK_90 62 60-69 M Outside M~ South ~ Samsun~ NA 2015-06-08
## 13 SK_98 58 50-59 M Outside M~ South ~ Samsun~ 2015-06-04 2015-06-09
## 14 SK_123 65 60-69 M Outside M~ South ~ Samsun~ 2015-06-07 2015-06-11
## # ... with 6 more variables: week_report <fct>, dt_start_exp <date>,
## # dt_end_exp <date>, dt_diag <date>, outcome <fct>, dt_death <date>, and
## # abbreviated variable names 1: place_infect, 2: reporting_ctry, 3: loc_hosp
##
## // contacts
##
## # A tibble: 33 x 4
## from to exposure diff_dt_onset
## <chr> <chr> <fct> <int>
## 1 SK_14 SK_113 Emergency room 10
## 2 SK_14 SK_116 Emergency room 13
## 3 SK_14 SK_41 Emergency room 14
## 4 SK_14 SK_112 Emergency room 14
## 5 SK_14 SK_100 Emergency room 15
## 6 SK_14 SK_114 Emergency room 15
## 7 SK_14 SK_136 Emergency room 15
## 8 SK_14 SK_47 Emergency room 16
## 9 SK_14 SK_110 Emergency room 16
## 10 SK_14 SK_122 Emergency room 16
## # ... with 23 more rowsIn addition to subsetting by node and edge attributes, networks can be pruned to only include components that are connected to certain nodes. The “id” argument takes a vector of nodes and returns the line list of individuals that “touch” those IDs.
##
## /// Epidemiological Contacts //
##
## // class: epicontacts
## // 97 cases in linelist; 98 contacts; non directed
##
## // linelist
##
## # A tibble: 97 x 15
## id age age_class sex place_inf~1 repor~2 loc_h~3 dt_onset dt_report
## <chr> <int> <chr> <fct> <fct> <fct> <fct> <date> <date>
## 1 SK_1 68 60-69 M Middle East South ~ Pyeong~ 2015-05-11 2015-05-19
## 2 SK_2 63 60-69 F Outside Mi~ South ~ Pyeong~ 2015-05-18 2015-05-20
## 3 SK_3 76 70-79 M Outside Mi~ South ~ Pyeong~ 2015-05-20 2015-05-20
## 4 SK_4 46 40-49 F Outside Mi~ South ~ Pyeong~ 2015-05-25 2015-05-26
## 5 SK_5 50 50-59 M Outside Mi~ South ~ 365 Ye~ 2015-05-25 2015-05-27
## 6 SK_6 71 70-79 M Outside Mi~ South ~ Pyeong~ 2015-05-24 2015-05-28
## 7 SK_7 28 20-29 F Outside Mi~ South ~ Pyeong~ 2015-05-21 2015-05-28
## 8 SK_8 46 40-49 F Outside Mi~ South ~ Seoul ~ 2015-05-26 2015-05-29
## 9 SK_10 44 40-49 M Outside Mi~ China Pyeong~ 2015-05-21 2015-05-29
## 10 SK_11 79 70-79 F Outside Mi~ South ~ Pyeong~ 2015-05-20 2015-05-29
## # ... with 87 more rows, 6 more variables: week_report <fct>,
## # dt_start_exp <date>, dt_end_exp <date>, dt_diag <date>, outcome <fct>,
## # dt_death <date>, and abbreviated variable names 1: place_infect,
## # 2: reporting_ctry, 3: loc_hosp
##
## // contacts
##
## # A tibble: 98 x 4
## from to exposure diff_dt_onset
## <chr> <chr> <fct> <int>
## 1 SK_14 SK_113 Emergency room 10
## 2 SK_14 SK_116 Emergency room 13
## 3 SK_14 SK_41 Emergency room 14
## 4 SK_14 SK_112 Emergency room 14
## 5 SK_14 SK_100 Emergency room 15
## 6 SK_14 SK_114 Emergency room 15
## 7 SK_14 SK_136 Emergency room 15
## 8 SK_14 SK_47 Emergency room 16
## 9 SK_14 SK_110 Emergency room 16
## 10 SK_14 SK_122 Emergency room 16
## # ... with 88 more rowsThe subset() method for epicontacts objects also accepts cluster size parameters (see “cs”, “cs_min” and “cs_max” arguments).
subset(merskor15, cs = 3)##
## /// Epidemiological Contacts //
##
## // class: epicontacts
## // 3 cases in linelist; 2 contacts; non directed
##
## // linelist
##
## # A tibble: 3 x 15
## id age age_class sex place_inf~1 repor~2 loc_h~3 dt_onset dt_report
## <chr> <int> <chr> <fct> <fct> <fct> <fct> <date> <date>
## 1 SK_76 75 70-79 F Outside Mi~ South ~ Samsun~ 2015-06-05 2015-06-07
## 2 SK_145 37 30-39 M Outside Mi~ South ~ Samsun~ 2015-06-10 2015-06-13
## 3 SK_150 44 40-49 M Outside Mi~ South ~ Konkuk~ 2015-06-11 2015-06-14
## # ... with 6 more variables: week_report <fct>, dt_start_exp <date>,
## # dt_end_exp <date>, dt_diag <date>, outcome <fct>, dt_death <date>, and
## # abbreviated variable names 1: place_infect, 2: reporting_ctry, 3: loc_hosp
##
## // contacts
##
## # A tibble: 2 x 4
## from to exposure diff_dt_onset
## <chr> <chr> <fct> <int>
## 1 SK_76 SK_145 Contact with HCW 5
## 2 SK_76 SK_150 Hospital room 6
subset(merskor15, cs_min = 10, cs_max = 100)##
## /// Epidemiological Contacts //
##
## // class: epicontacts
## // 94 cases in linelist; 96 contacts; non directed
##
## // linelist
##
## # A tibble: 94 x 15
## id age age_class sex place_inf~1 repor~2 loc_h~3 dt_onset dt_report
## <chr> <int> <chr> <fct> <fct> <fct> <fct> <date> <date>
## 1 SK_1 68 60-69 M Middle East South ~ Pyeong~ 2015-05-11 2015-05-19
## 2 SK_2 63 60-69 F Outside Mi~ South ~ Pyeong~ 2015-05-18 2015-05-20
## 3 SK_3 76 70-79 M Outside Mi~ South ~ Pyeong~ 2015-05-20 2015-05-20
## 4 SK_4 46 40-49 F Outside Mi~ South ~ Pyeong~ 2015-05-25 2015-05-26
## 5 SK_5 50 50-59 M Outside Mi~ South ~ 365 Ye~ 2015-05-25 2015-05-27
## 6 SK_6 71 70-79 M Outside Mi~ South ~ Pyeong~ 2015-05-24 2015-05-28
## 7 SK_7 28 20-29 F Outside Mi~ South ~ Pyeong~ 2015-05-21 2015-05-28
## 8 SK_8 46 40-49 F Outside Mi~ South ~ Seoul ~ 2015-05-26 2015-05-29
## 9 SK_10 44 40-49 M Outside Mi~ China Pyeong~ 2015-05-21 2015-05-29
## 10 SK_11 79 70-79 F Outside Mi~ South ~ Pyeong~ 2015-05-20 2015-05-29
## # ... with 84 more rows, 6 more variables: week_report <fct>,
## # dt_start_exp <date>, dt_end_exp <date>, dt_diag <date>, outcome <fct>,
## # dt_death <date>, and abbreviated variable names 1: place_infect,
## # 2: reporting_ctry, 3: loc_hosp
##
## // contacts
##
## # A tibble: 96 x 4
## from to exposure diff_dt_onset
## <chr> <chr> <fct> <int>
## 1 SK_14 SK_113 Emergency room 10
## 2 SK_14 SK_116 Emergency room 13
## 3 SK_14 SK_41 Emergency room 14
## 4 SK_14 SK_112 Emergency room 14
## 5 SK_14 SK_100 Emergency room 15
## 6 SK_14 SK_114 Emergency room 15
## 7 SK_14 SK_136 Emergency room 15
## 8 SK_14 SK_47 Emergency room 16
## 9 SK_14 SK_110 Emergency room 16
## 10 SK_14 SK_122 Emergency room 16
## # ... with 86 more rowsVisualisation
Default Plotting Method
One of the main features of epicontacts is its visualisation capabilities. As a default, the package uses interactive plotting based on the visNetwork package1. This interactivity is particularly useful for visualising large datasets.
plot(merskor15) The above is a generic method based on the vis_epicontacts() and accepts a number of arguments to customize the plot appearance and functionality. For a full list of options use ?vis_epicontacts(). For instance, one can customize nodes using colors and icons:
See codeawesome to see available shapes.
Alternatively, the method used for plotting can be graph3D, in which case a 3-dimensional graph will be used (see below).
3D plots
epicontacts loads the threejs package to enable 3D visualisation tools with the graph3D() function2.
graph3D(merskor15, node_color = "sex", g_title = "MERS Korea 2014")To interact with the plot:
- zoom: scrollwheel
- rotate: left-mouse button + move
- pan: right-mouse button + move
- identify node by label: mouse over
Analysis
Extract Characteristics of Pairwise Nodes
The get_pairwise() function allows processing of variable(s) in the line list according to each pair in the contact dataset. For the following example, date of onset of disease is extracted from the line list in order to compute the difference between disease date of onset for each pair. The value that is produced from this comparison represents the serial interval (si).
si <- get_pairwise(merskor15, "dt_onset")
summary(si)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2.00 11.00 14.00 14.47 18.00 27.00
hist(si, col="grey", border="white", xlab="Days after symptoms",
main="MERS Korea 2014\nSerial Interval")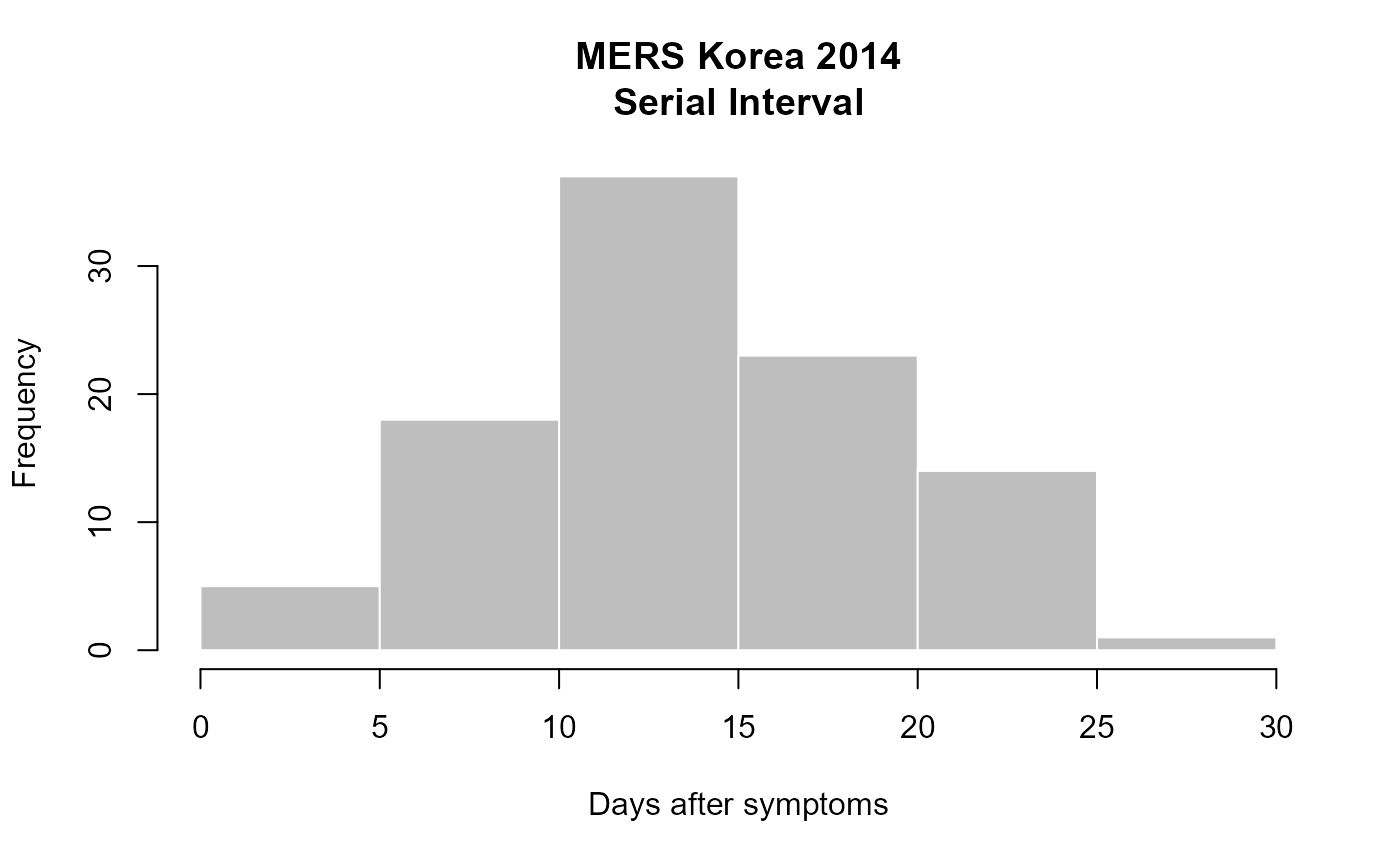
The get_pairwise() will interpret the class of the column being used for comparison, and will adjust its method of comparing the values accordingly. For numbers and dates (like the si example above), the function will subtract the values. When applied to columns that are characters or categorical, get_pairwise() will paste values together. Because the function also allows for arbitrary processing (see “f” argument), these discrete combinations can be easily tabulated and analyzed.
head(get_pairwise(merskor15, "sex"), n = 10)## [1] "M - M" "M - F" "M - F" "M - M" "M - F" "M - M" "M - M" "M - F" "M - F"
## [10] "M - F"
get_pairwise(merskor15, "sex", f=table)## values.to
## values.from F M
## F 2 4
## M 38 54
fisher.test(get_pairwise(merskor15, "sex", f=table)) ##
## Fisher's Exact Test for Count Data
##
## data: get_pairwise(merskor15, "sex", f = table)
## p-value = 1
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.06158088 5.26628732
## sample estimates:
## odds ratio
## 0.712926Identify Clusters
The get_clusters() function can be used for to identify connected components in an epicontacts object. Here, we illustrate its use to study contact patterns in a simulated Ebola outbreak. First, we use it to retrieve data.frame containing the cluster information:
x <- make_epicontacts(ebola_sim$linelist, ebola_sim$contacts,
id = "case_id", to = "case_id", from = "infector",
directed = TRUE)
x##
## /// Epidemiological Contacts //
##
## // class: epicontacts
## // 5,888 cases in linelist; 3,800 contacts; directed
##
## // linelist
##
## # A tibble: 5,888 x 11
## id generation date_of_i~1 date_of_~2 date_of_~3 date_of_~4 outcome gender
## <chr> <int> <date> <date> <date> <date> <fct> <fct>
## 1 d1fafd 0 NA 2014-04-07 2014-04-17 2014-04-19 <NA> f
## 2 53371b 1 2014-04-09 2014-04-15 2014-04-20 NA <NA> m
## 3 f5c3d8 1 2014-04-18 2014-04-21 2014-04-25 2014-04-30 Recover f
## 4 6c286a 2 NA 2014-04-27 2014-04-27 2014-05-07 Death f
## 5 0f58c4 2 2014-04-22 2014-04-26 2014-04-29 2014-05-17 Recover f
## 6 49731d 0 2014-03-19 2014-04-25 2014-05-02 2014-05-07 <NA> f
## 7 f9149b 3 NA 2014-05-03 2014-05-04 NA Recover f
## 8 881bd4 3 2014-04-26 2014-05-01 2014-05-05 NA Death f
## 9 e66fa4 2 NA 2014-04-21 2014-05-06 2014-05-12 Recover m
## 10 20b688 3 NA 2014-05-05 2014-05-06 2014-05-14 Death m
## # ... with 5,878 more rows, 3 more variables: hospital <fct>, lon <dbl>,
## # lat <dbl>, and abbreviated variable names 1: date_of_infection,
## # 2: date_of_onset, 3: date_of_hospitalisation, 4: date_of_outcome
##
## // contacts
##
## # A tibble: 3,800 x 3
## from to source
## <chr> <chr> <fct>
## 1 d1fafd 53371b other
## 2 cac51e f5c3d8 funeral
## 3 f5c3d8 0f58c4 other
## 4 0f58c4 881bd4 other
## 5 8508df 40ae5f other
## 6 127d83 f547d6 funeral
## 7 f5c3d8 d58402 other
## 8 20b688 d8a13d other
## 9 2ae019 a3c8b8 other
## 10 20b688 974bc1 other
## # ... with 3,790 more rows
clust <- get_clusters(x, output = "data.frame")
class(clust)## [1] "data.frame"
dim(clust)## [1] 7047 3
table(clust$cluster_size)##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14
## 1536 1680 1182 784 545 342 308 208 171 100 99 24 26 42
barplot(table(clust$cluster_size),
main = "Cluster size distribution",
xlab = "Cluster size",
ylab = "Frequency")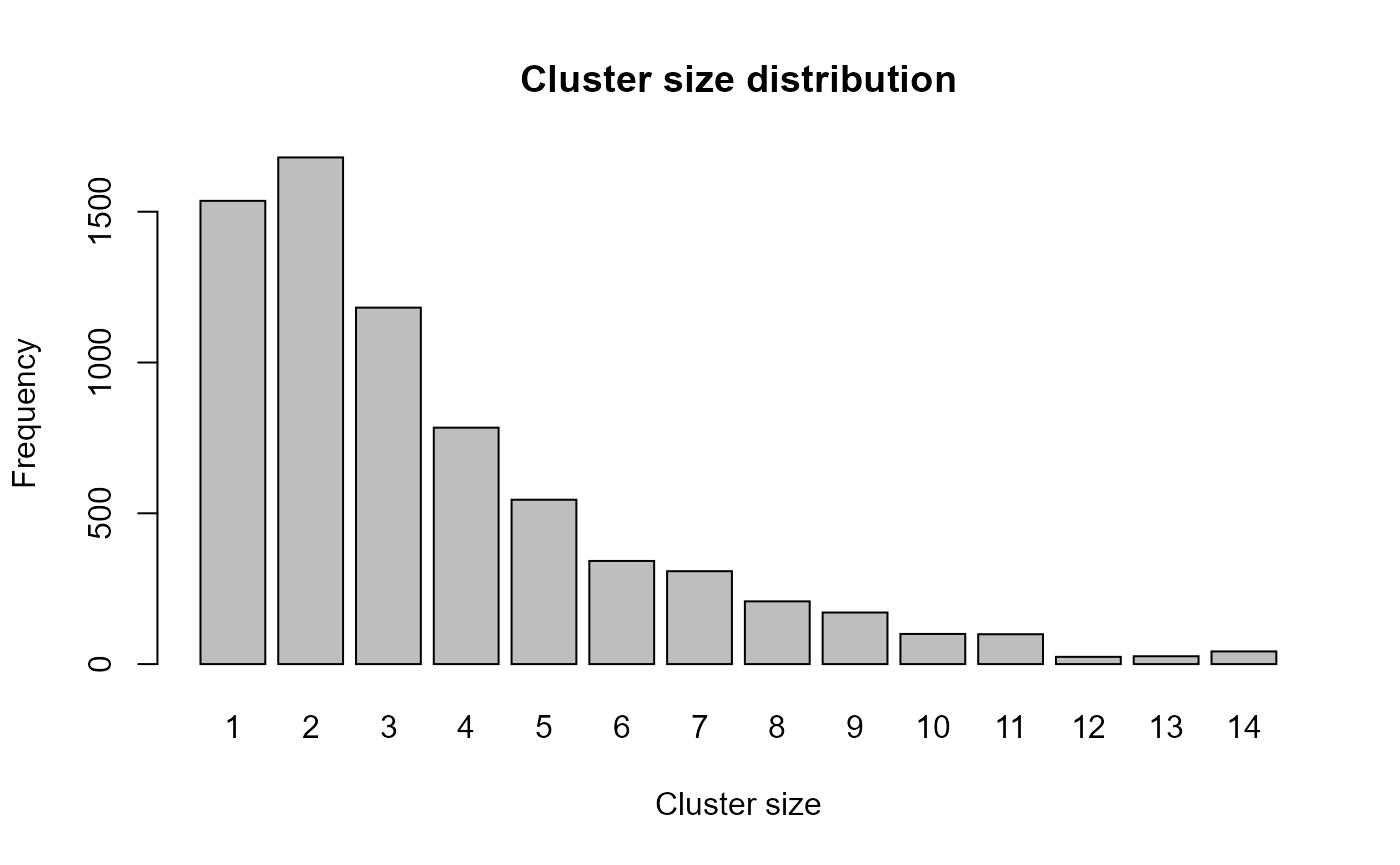
Let us look at the largest clusters. For this, we add cluster information to the epicontacts object, and then subset it:
x <- get_clusters(x)
x_14 <- subset(x, cs = 14)
plot(x_14, "cluster_member")Calculate Degree
The degree of a node corresponds to its number of edges or connections to other nodes. get_degree() provides an easy method for calculating this value for epicontacts networks. A high degree in this context indicates an individual who was in contact with many others.
nb use of “type” argument depends on whether or not the network is directed.
deg_both <- get_degree(merskor15, "both", only_linelist = TRUE)Which individuals have the ten most contacts?
## SK_14 SK_1 SK_16 SK_15 SK_6 SK_39 SK_11 SK_12 SK_76 SK_87
## 39 26 22 5 3 3 2 2 2 2What is the mean number of contacts?
mean(deg_both)## [1] 1.209877